Selected Figures
Yixin Zhu1, Tao Gao1, Lifeng Fan1, Siyuan Huang1, Mark Edmonds1, Hangxin Liu1, Feng Gao1, Chi Zhang1, Siyuan Qi1, Ying Nian Wu1, Josh B. Tenenbaum2, and Song-Chun Zhu1
1 Center for Vision, Cognition, Learning, and Autonomy (VCLA), UCLA | 2 Center for Brains, Minds, and Machines (CBMM), MIT
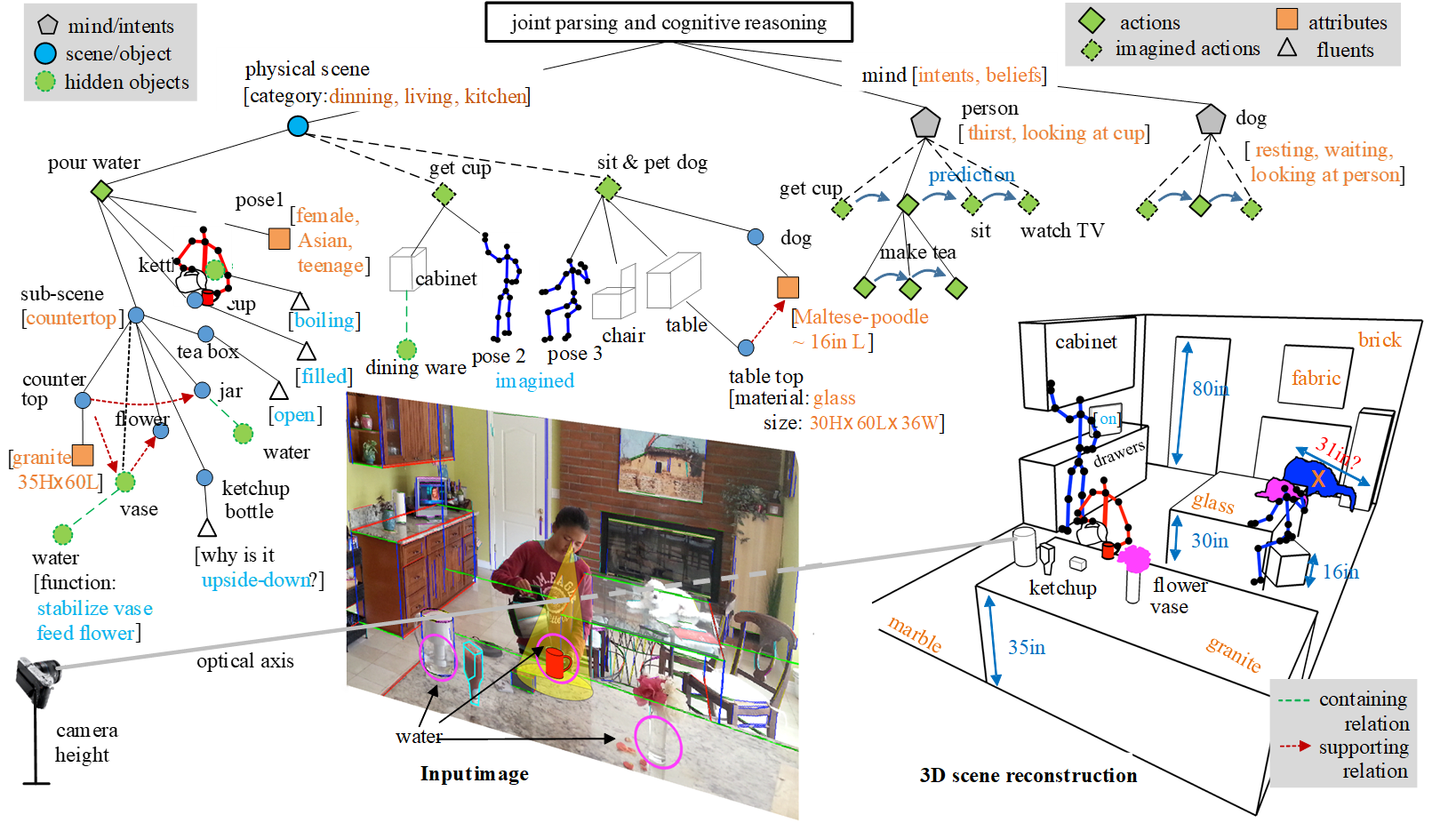
Recent progress in deep learning is essentially based on a “big data for small tasks” paradigm, under which massive amounts of data are used to train a classifier for a single narrow task. In this paper, we call for a shift that flips this paradigm upside down. Specifically, we propose a “small data for big tasks” paradigm, wherein a single artificial intelligence (AI) system is challenged to develop “common sense,” enabling it to solve a wide range of tasks with little training data. We illustrate the potential power of this new paradigm by reviewing models of common sense that synthesize recent breakthroughs in both machine and human vision.We identify functionality, physics, intent, causality, and utility (FPICU) as the five core domains of cognitive AI with humanlike common sense. When taken as a unified concept, FPICU is concerned with the questions of “why” and “how,” beyond the dominant “what” and “where” framework for understanding vision. They are invisible in terms of pixels but nevertheless drive the creation,maintenance, and development of visual scenes. We therefore coin them the “dark matter” of vision. Just as our universe cannot be understood by merely studying observable matter, we argue that vision cannot be understood without studying FPICU. We demonstrate the power of this perspective to develop cognitive AI systems with humanlike common sense by showing how to observe and apply FPICU with little training data to solve a wide range of challenging tasks, including tool use, planning, utility inference, and social learning. In summary, we argue that the next generation of AI must embrace “dark” humanlike common sense for solving novel tasks.
@article{zhu2020dark,
title={Dark, Beyond Deep: A Paradigm Shift to Cognitive AI with Humanlike Common Sense},
author={Zhu, Y and Gao, T and Fan, L and Huang, S and Edmonds, M and Liu, H and Gao, F and Zhang, C and Qi, S and Wu, YN and others},
journal={Engineering},
volume={42},
number={1},
pages={27--45},
year={2020}
}